들어가기에 앞서
-
논문: Language Models are Few-Shot Learners
해당 포스트는 논문과 다음의 2개의 유튜브 영상을 보며 정리하였습니다. 논문의 내용을 기본으로 했지만, 필요에 따라 공부한 것들을 추가하였습니다.
그 중에서도 Yannic Kilcher의 채널은 최근 엄청난 속도로 최신 논문들을 리뷰해주는 유튜브 채널이다.(정말 멋있는 연구자 및 유튜버) 다른 무엇보다 최대 강점은 논문이 나온지 1~2일만에 리뷰를 해주며, 실제로 논문을 high level에서 핵심 아이디어만 짚어준다는 것이다. 이러한 NLP 이외에도 정말 흥미로운 딥러닝 논문 리뷰들이 많으니 꼭 한번 방문해서 살펴보세요! 😁
- Minsuk Heo 허민석: [논문 리뷰] GPT-3
- Yannic Kilcher: GPT-3: Language Models are Few-Shot Learners (Paper Explained)
논문 한 줄 요약
어마무시한 파라미터(1,750억개)를 가지고 fine-tuning 없이 few-shot learning을 통해 몇몇 NLP task에서 좋은 성능을 보였다.
0. Abstract
많은 언어 모델들은 현재 pre-training → fine-tuning 하는 방식으로 학습되고 있는데, 이는 추가적인 많은 레이블되어 있는 데이터셋이 필요하다. 많은 리소스를 필요로 한다는 문제점과 더불어 애초에 사람은 몇 안되는 예제를 통해서도 새로운 NLP task를 수행할 수 있다.
- 이러한 관점에서 GPT-3는 파리미터의 수를 1,750억개까지 늘리고, fine-tuning과 gradient updates 없이 few-shot demonstrations만을 통해 NLP task에서 경쟁력 있는 결과를 얻었다. (전부 다 SOTA를 달성한 것은 아니다.)
- translation, question-answering, cloze(missing 단어를 채워 넣는 테스크) task, unscrambling words, 3-digit arithmetic(세자리 산수) 등에서 좋은 결과를 보였다.
- 또한 GPT-3는 사람이 구별 불가능한 정도의 신문 기사를 작성하기도 하였다.
- 그 외 해당 모델과 관련한 사회적 이슈에 대해서도 다룬다.
1. Introduction
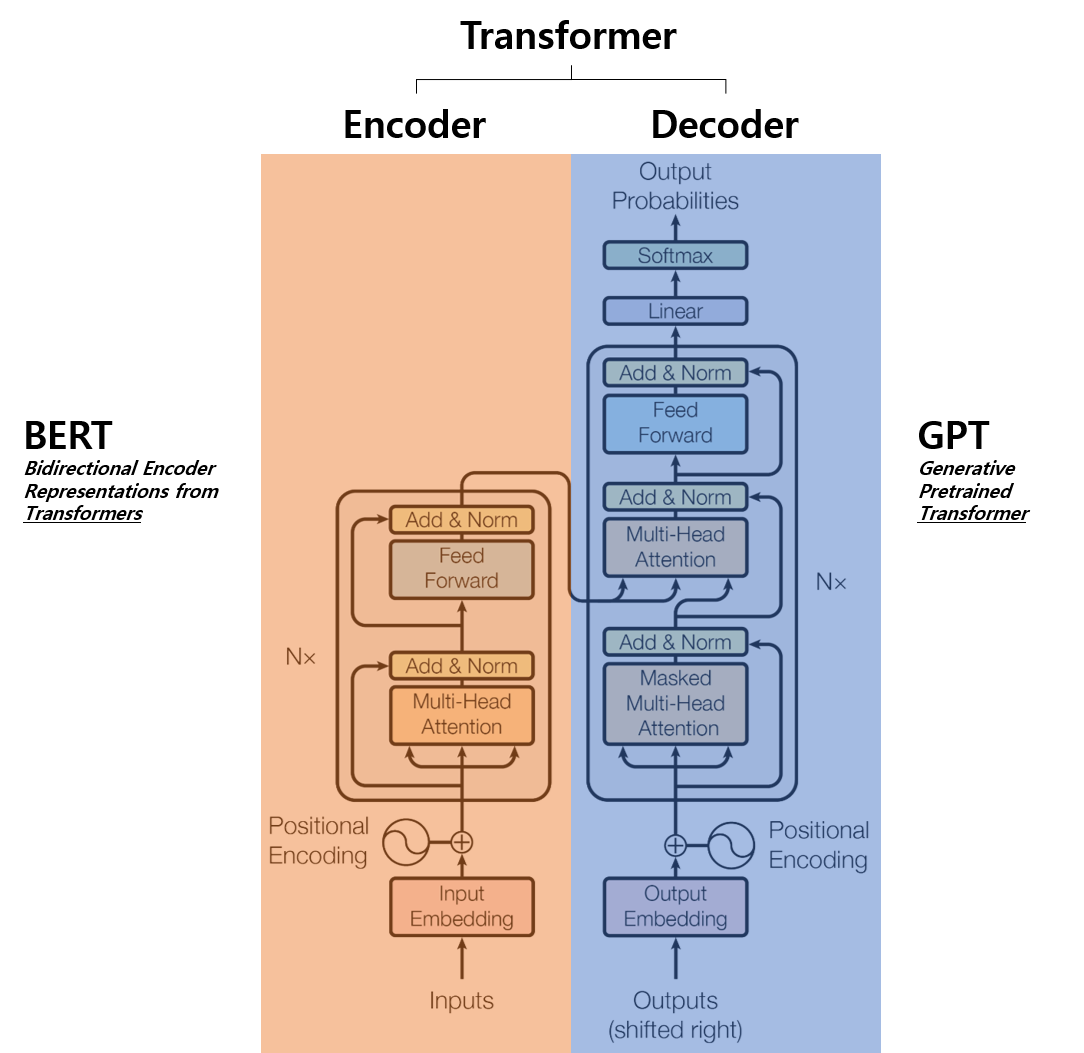
GPT (Generative Pretrained Transformer)는 Transformer의 Decoder 부분을, BERT (Bidirectional Encoder Representations from Transformer)는 Transformer의 Encoder를 사용하고 있기 때문에 그 관계가 쌍둥이 자매와 같다. 실제로 그 발전의 역사를 보면 ELMO (2018.02) → GPT-1 (2018.05) → BERT (2018.10) → XLNet (2019.07) → GPT-2 (2019.02) → RoBERTa (2019.07) → ALBERT (2019.09) → T5 (2019.10) → ... 처럼 같은 Transformer에서 출발해서 서로의 성능을 엎치락 뒤치락하면서 발전해왔다. 기나긴 선의의 경쟁 끝에 마침내 이번에는 GPT를 줄곧 연구해온 OpenAI에서 2020년 05월 GPT-3 모델을 들고나왔다.
GPT → GPT-2
- Layer normalization이 각각의 input의 sub-block으로 옮겨졌으며, 마지막 self-attention block에도 더해짐.
- A modified initialization which accounts for the accumulation on the residual path with model depth is used.
- residual layer에서 initialization 가중치를 scaling.
- vocabulary 50,257개까지 증가.
- context size를 512에서 1024로 증가. 배치 사이즈를 512개로 증가.
GPT-2 → GPT-3
- Transformer 부분에서 dense and locally banded sparse attention pattern를 사용.
앞선 여러 언어 모델들은 일반적인 언어에 pre-trained 하고, 특정 task에 맞게 fine-tuning하게 되는데 애초에 이 fine-tuning하는 과정이 만만치 않다.
- fine-tuning을 위해선 pre-trained을 잘 했다고해도, 해당 task를 위한 레이블되어 있는 양질의 데이터셋이 또 다시 필요.
- fine-tuning을 위한 데이터셋을 학습시키는 데 또 다른 가중치 업데이트 과정이 필연적.
- 특정 task에 fine-tuning 하는 것은 일반적으로 사람이 언어를 이해하는 방법은 아님.
- 거대한 데이터셋에 pre-trained 한 후, fine-tuning 하는 것은 narrow task(특정 task에 대해서만 학습)에만 학습하는 것.
즉, pre-trained + fine-tuning 패러다임은 여러 문제가 있다.

-
언어 모델을 학습시키는 동안
in-context learning으로 다양한 패턴 인지 능력을 학습하는 방법을 사용 -
사칙연산, 오타 검색, 번역 등의 패턴을 few-shot learning으로 학습할 수 있음

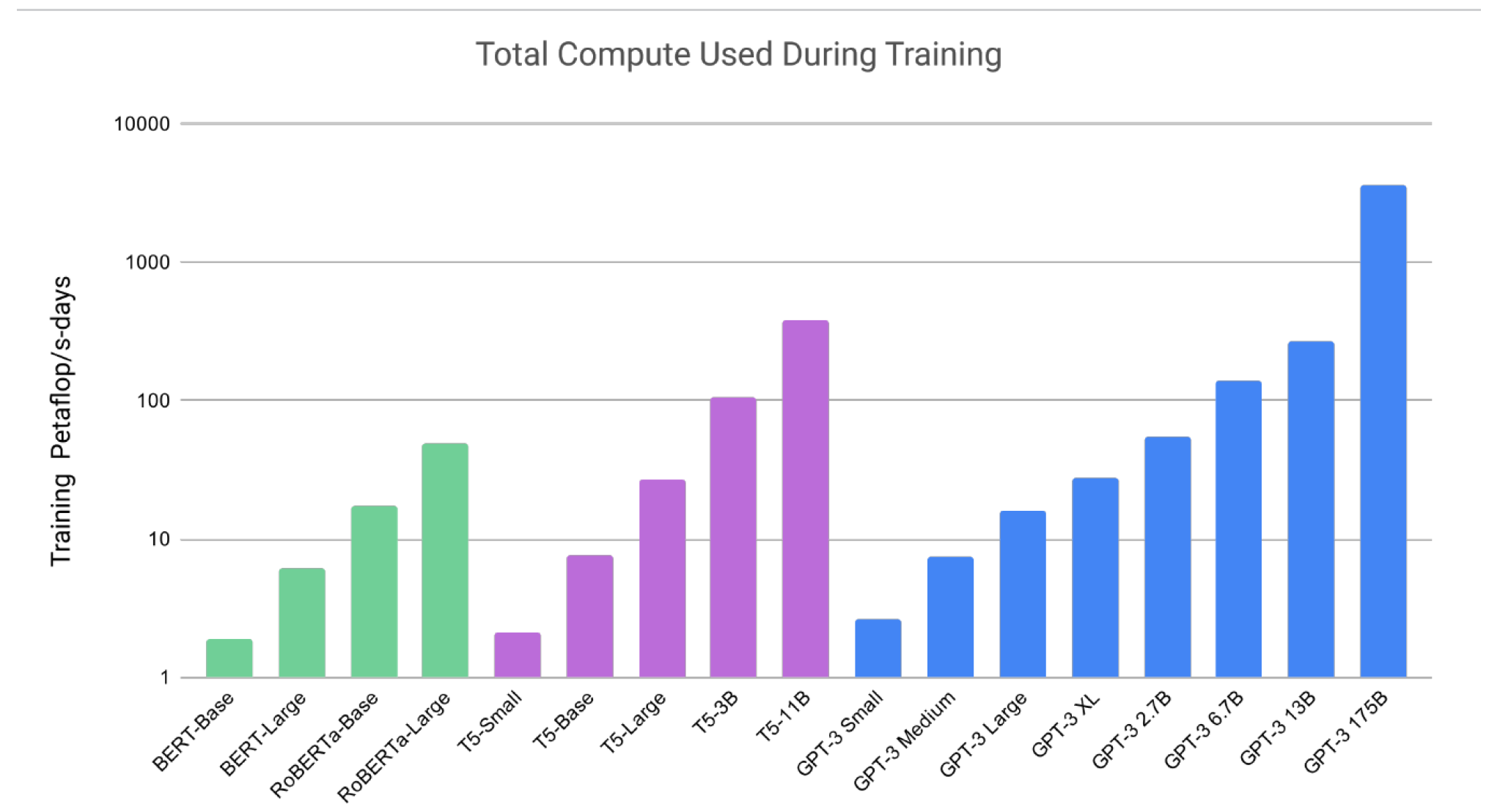
- 위의 그래프에서 확인할 수 있듯이, in-context learning의 경우 거대한 모델(많은 파라미터)을 사용할 수 록 그 성능이 압도적으로 향상됨.
따라서 본 논문에서 소개하는 GPT-3는 한마디로 Transformer의 decoder 부분을 Autoregressive 방법으로 few-shot 학습한 fine-tuning 과정없는 다용도 자연어 처리 모델 이다.
언어 모델은 fluidity과 generality를 가져야 한다.
다시 정리하면 해당 논문이 다루는 핵심은 다음과 같다.
- 파라미터 1,750억개의 Autoregressive(전에 나온 토큰들을 기반으로 다음 토큰을 예측하는 언어 모델 종류) 모델을 사용하여 in-context learning 능력을 평가할 때, (24개의 NLP dataset들을 이용하는 task와 기존의 dataset에 들어있지 않은 정보에 대한 새로운 task에 대해 평가) 3가지의 학습 방법을 사용
"few-shot learning": 몇 개의 (10개에서 100개) demonstrations(설명 예제)만 보여줌"one-shot learning": 한 개의 demonstration만 보여줌"zero-shot learning": 어느 demonstration도 보여주지 않고, 자연어에 대한 instruction만 보여줌 (아직 정확히 이해하지 못함.)
- GPT-3를 fine-tuning 할 수 있지만 본 논문에서는 다루지 않고 future work으로 남겨둔다.
- zero-shot과 one-shot에서 promising한 결과를 보여주었고, few-shot가 몇몇의 task에서는 SOTA를 달성.
- ex) CoQA: 85.0 F1, TriviaQA: 71.2% 정확도 달성
- on-the-fly reasoning (바로바로(여러 문맥을 보지 않고? 속도?) 추론해야하는) task에서도 좋은 결과를 보임.
- ex) unscrambling words / performing arithmetic / using novel words in a sentence after seeing them defined only once.
-
사람이 분별할 수 없는 뉴스 기사 작성.
- 이러한 GPT-3의 거대한 크기에도 few-shot learning이 제대로된 성능을 발휘하지 못한 NLP task가 있음.
- 추론 문제 ANLI 데이터셋과 독해 문제 RACE, QuAC 데이터셋
-
GPT-3의 한계점.
-
Commom Crawl 시에 데이터 오염 문제 정도를 측정하는 방법 제안.
-
비교적 적은 모델(1.25억에서 130억개의 파라미터)들을 사용하여 실험.
- 이러한 넓은 활용성으로 인한 bias, fairness, broader societal impact를 다룸.
2. Approach
본 논문의 접근 방식은 모델, 데이터, 학습 등 여러 면에서 GPT-2와 비슷하지만, 모델의 크기를 확장하고 데이터셋의 크기와 다양성, 학습 과정을 증가시켰다. 본 내용을 시작하기 전에 해당 용어들에 대한 정의와 차이점들을 다뤄본다.

-
Fine-Tuning (FT)보통 몇 천 또는 몇 백개의 레이블 되어 있는 데이터셋을 사용한다. 가장 큰 장점은 여러 benchmark에서 강력한 성능을 낸다는 것이다. 그러나 각각의 task에 대해 새로운 큰 데이터셋이 필요할 뿐 만 아니라 일반화가 부족하다는 것이 약점으로 뽑힌다. 또한, 학습 데이터셋의 잘못된 feature를 이용할지도 모른다. 따라서 본 논문에서는 task의 영향을 받지 않는(task-agnostic) 성능을 보이기 위해 FT는 사용하지 않으나, 차후 사용할 수 있으며 실제로는 유망한 방법이다. -
Few-Shot (FS)모델에 몇 개의 demonstrations만 보여주고, 가중치 업데이트를 허용하지 않는다고 하는데, 가중치를 업데이트 하지 않는다면 이를 learning이라 부를 수 있는 지와 실제로 무슨 의미가 있는지 아직은 이해되지 않는다. 원문은 다음과 같다.
the model is given a few demonstrations of the task at inference time as conditioning, but no weight updates are allowed.
- 영어에서 불어로 번역하는 예를 들면, $K$개의 영어와 그에 대응하는 불어 예시를 모델에게 보여주고 마지막 하나의 예시에서 영어가 주어졌을 때, 불어를 예측해보도록 하는 것이다. 이 부분도 위에서와 같은 맥락으로 완벽히 이해하지 못했으며 원문은 다음과 같다.
for a typical dataset an example has a context and a desired completion (for example an English sentence and the French translation), and few-shot works by giving K examples of context and completion, and then one final example of context, with the model expected to provide the completion.
-
$K$는 보통 10에서 100이며, 모델의 context window에 따라 다르다. FS의 장점은 당연히 많은 데이터양을 필요로 하지 않으며, 많지만 협소한 fine-tuning용 데이터셋을 학습하는 가능성을 줄인다.
-
One-Shot (1S)1S은 하나의 demonstration만 보여주는 것을 제외하고는 FS와 동일하다. -
Zero-Shot (0S)0S는 어느 demonstration도 보여주지 않는 다는 것을 제외하고는 1S와 동일하다. 가장 편의적이고, 강건하며, 잘못된 정보를 습득할 확률을 줄여주는 방법이지만, 위의 세 가지 중 가장 어려운 방법이기도 하다. (심지어 사람에게도 어려운 task일 수 있다.)
2.1 Model and Architectures

사용된 모델은 GPT-2랑 동일하지만 (modified initialization, pre-normalization, reversible tokenization), Transformer 부분에서 dense and locally banded sparse attention pattern를 사용했다. (d아키텍쳐)
2.2 Training Dataset
Common Crawl dataset의 웹크롤링 데이터셋을 사용하였고, 그대로 사용하는 것은 별로 좋지 않은 결과를 내어 다음 3가지 전처리 과정을 진행하였다.
- CommonCrawl 데이터셋을 high-quality reference corpora로 필터링하고,
- 문서 레벨에서 fuzzy deduplication를 수행하고,
- high-quality reference corpora(WebText 등)를 학습시에 추가하였다.

2.3 Training Process
2.4 Evaluation
3. Results
GPT의 고질적인 문제는 양방향 정보를 획득할 수 없다는 것인데, 이 점이 성능 평가에서 고스란히 나타났다.